

今回は、今年の2月23日に発表された「Stable Diffusion 3」のAPIが4月17日に公開されたので使い方を紹介していきたいと思います。
はじめに
Stable Diffusion 3 の概要
Stable Diffusion 3は、画像生成技術の最先端を担う高性能なモデルです。このモデルは、複数主題のプロンプト対応、画質の向上、スペリング能力の改善など、多面的なパフォーマンス向上を実現しています。今回のアップグレードにより、ユーザーは以前よりもずっと洗練された画像を生成できるようになりました。
技術革新
Stable Diffusion 3の核となるのは、「拡散トランスフォーマー・アーキテクチャ」と「フロー・マッチング」の革新的な組み合わせです。これにより、モデルは以前のバージョンよりも複雑で詳細な画像を生成する能力が格段に向上しています。
パフォーマンスの向上
Stable Diffusion 3は、特に画質と反応性が大幅に改善されています。たとえば、より精密なディテールと色彩表現を実現することで、リアルな画像生成が可能になっています。また、スペリング能力の向上は、テキストベースのプロンプトがより正確に反映されることを意味しており、ユーザーの意図するとおりの結果が得やすくなっています。
アクセスとスケーラビリティ
このモデルは、800Mから8Bに及ぶパラメータを提供し、さまざまなニーズに対応できる柔軟性を持っています。これにより、個人のクリエーターから大企業まで、多岐にわたるユーザーが自らの創造的なビジョンを実現するためのサポートを受けることが可能です。
安全性と倫理
Stable Diffusion 3の開発は、安全で責任あるAIの実践に基づいています。悪用を防ぐための複数の安全対策が導入されており、モデルのトレーニングから展開に至るまで、一貫してセキュリティが考慮されています。さらに、研究者や専門家との連携を通じて、安全なAI使用のための新たな基準を模索しています。
Stable Diffusion 3 の特徴
技術的進化
Stable Diffusion 3は、画像とテキストの両方のモダリティを考慮に入れた新しいアーキテクチャ、Multimodal Diffusion Transformer (MMDiT)を導入しています。これにより、テキスト理解とスペリングの能力が以前のバージョンよりも向上しました。特に、画像と言語表現用に別々の重みセットを使用することで、より精確なテキストアラインメントとビジュアル表現が可能になっています。
性能の向上と競合比較
Stable Diffusion 3は、DALL·E 3、Midjourney v6、Ideogram v1などの既存のテキストから画像への生成システムと比較して、タイポグラフィーとプロンプトの遵守において優れた性能を発揮します。これは、ビジュアルエステティックス、プロンプトフォローイング、タイポグラフィーにおける人間の評価に基づくもので、Stable Diffusion 3がこれらの領域で他のモデルを同等かそれ以上に上回っていることを示しています。
新しいRectified Flow (RF)方式の導入
Stable Diffusion 3では、データとノイズを線形軌道で結びつける新しいRectified Flow (RF)方式を採用しています。これにより、より直線的な推論パスを実現し、サンプリングステップ数を減らすことができます。さらに、トレーニングプロセスに新しい軌道サンプリングスケジュールを導入し、より困難な予測タスクに重みを置くことで全体のパフォーマンスが向上しています。
拡張性と柔軟性
800Mから8Bのパラメータを持ったことで、異なるハードウェアの制約をさらに解消し、より多くのユーザーがこの先進的なモデルを利用できるようになります。
Stable Diffusion3 の使い方
使用方法
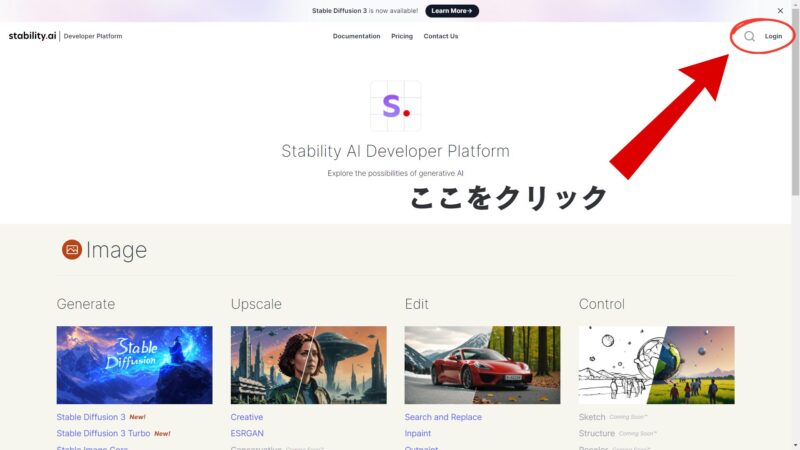
まずは右上の「Login」をクリック
LoginができたらAPIキーを取得する
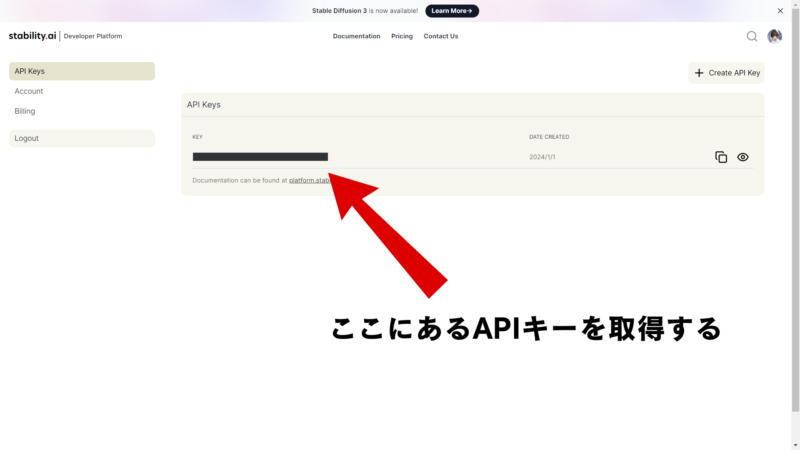
APIキーを取得したらAPI Referenceからサンプルコードをコピーし、Pythonで実行
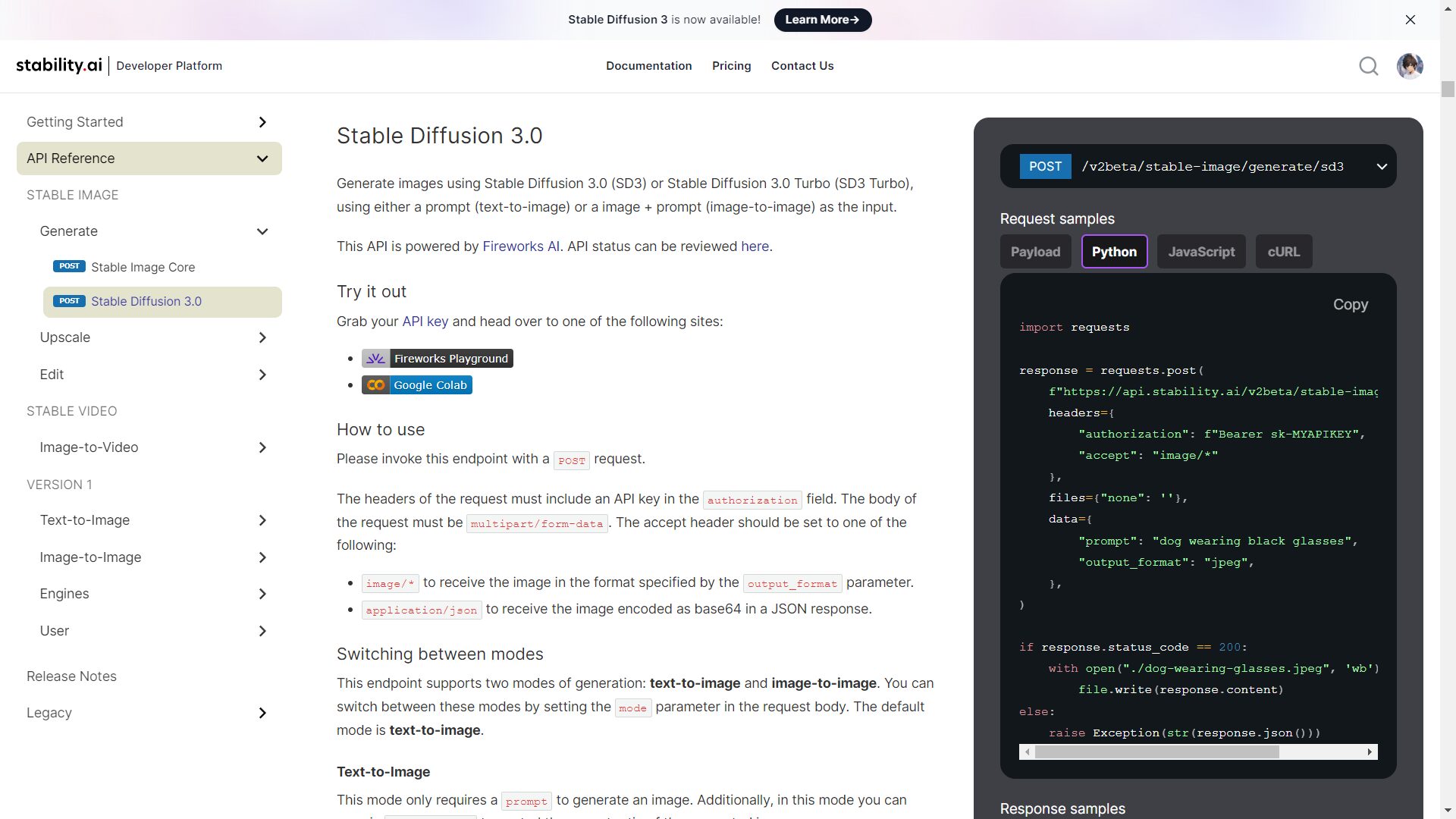
import requests
response = requests.post(
f"https://api.stability.ai/v2beta/stable-image/generate/sd3",
headers={
"authorization": "ここに取得したAPIキーを入力",
"accept": "image/*"
},
files={"none": ''},
data={
"prompt": "dog wearing black glasses",
"output_format": "jpeg",
},
)
if response.status_code == 200:
with open("./dog-wearing-glasses.jpeg", 'wb') as file:
file.write(response.content)
else:
raise Exception(str(response.json()))
デフォルトのままでいくと犬が眼鏡をかけている画像ができます。
“prompt”: “dog wearing black glasses“,
ここに自分の作りたい画像をテキストにして入れてください。

一通りの流れを動画にしたので参考程度にしてください
まとめ
今回は、Stable Diffusion 3 の使い方の紹介をしました。Diffusion モデルというのはいろいろな場面で使われることが増えてきたのでぜひ試してみてください!もしわからない教えてほしいなどありましたら気軽にお問い合わせください。

Stable Diffusionの使い方はWeb3.0メディア「meta land」の「Stable Diffusionの使い方とコツを初心者向けに解説!無料の画像生成AIとは?」記事も分かりやすいのでおすすめですよ。