

今回は、ChatGPTに関しての2つの論文についての解説します。1つ目に紹介する論文は、プロンプトに関する研究論文。2つ目に紹介する論文は、ChatGPTが2023年3月から6月までの研究で応答が劣化したという研究論文になります。これからこの2つの論文についてわかりやすく解説していきたいと思います!
はじめに

ChatGPTとは?
ChatGPTは、人間のような自然な会話を生成するAIです。OpenAIによって開発され、大量のテキストデータを用いて訓練されました。その結果、ChatGPTは人間のような自然なテキストを生成する能力を持つようになりました。
言語モデルのパフォーマンス分析

まず最初の言語モデルのパフォーマンス分析した論文から説明していきます。ここでは、言語モデルにどのようにプロンプトを入れたらいいか学ぶことができます。
言語モデルと長いコンテキスト
言語モデルは、与えられたコンテキストに基づいて次の単語やフレーズを予測する能力を持っています。しかし、コンテキストが長くなると、その全体を効果的に処理することが難しくなります。
言語モデルが長いコンテキストをどのように扱うのか
ここ最近SNSを見ているとプロンプトが異様に長かったりするのを見かけることが増えてきました。しかし、次の表を見ると「あれ?」となります。
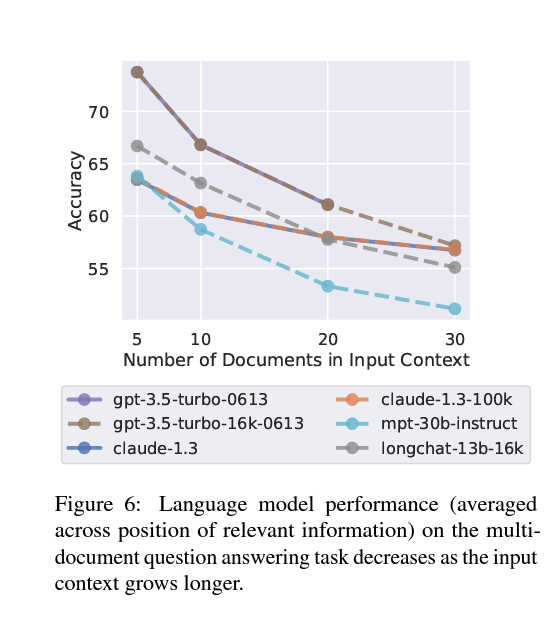
この表を見てわかることは、長いコンテキストだとパフォーマンスが低下するということ。おそらくプロンプトが長すぎると重要な情報がどこにあるのかわからなくなるのだと思う。つまり、高いパフォーマンスを発揮させたいならプロンプトの長さはなるべく短い方がいい。
関連情報の位置によるパフォーマンスの変動
次は、言語モデルの性能は重要な情報がどこにあるかによって変わるということがわかります。
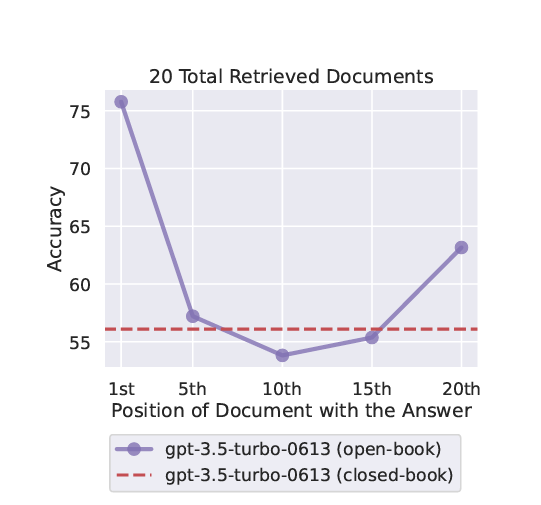
この表を見ると真ん中がかなり下がっていることがわかる。これが表しているのは、言語モデルの性能は重要な情報が「最初と最後」にあると、モデルの性能あがるということ。しかし、重要な情報が中間地点にある時は、その情報を見落とすことがあり結果が悪くなることがある。これは、言語モデルが文章全体を平等に扱うのが難しいから。
複数の大規模言語モデルで実験済
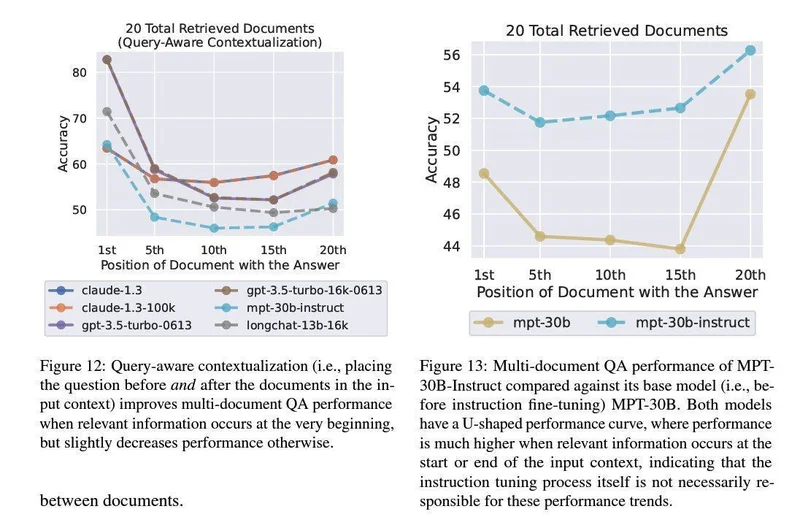
この実験は、複数の大規模言語モデルのデータを分析した結果になります。MPT-30B-Instruct、LongChat-13B(16K)、GPT-3.5-Turboなどの言語モデルを研究で「最初と最後」が重要であることがわかった。
GPT-4のパフォーマンスは?
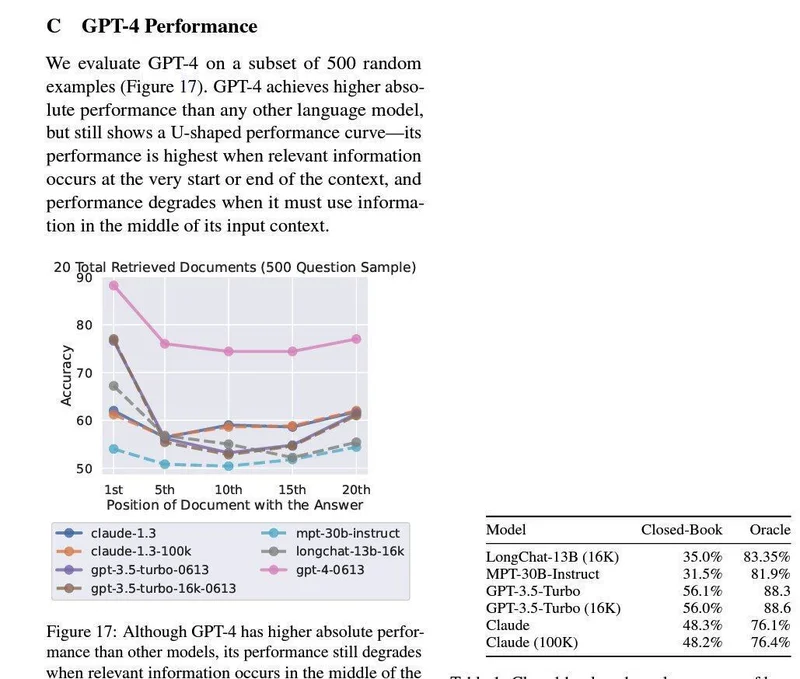
じゃあGPT-4はどうなの?ということで実験がされていてその結果が上の表です。ピンクの線がGPT-4です。他の大規模言語モデルに比べて明らかにパフォーマンスが高いことを示しています。しかし、GPT-4といえど中間地点のパフォーマンスが下がっていることがわかる。
ChatGPTが劣化!?

4つのタスクの研究
ここでは、SNSで話題になった別の1つの論文について解説します。この論文は、GPT-3.5とGPT-4の進化とパフォーマンスについて書かれています。それは4つのタスク―「数学問題解決」「センシティブな質問への対応」「コード生成」「視覚的推論」―における研究結果を取り扱っています。
数学問題
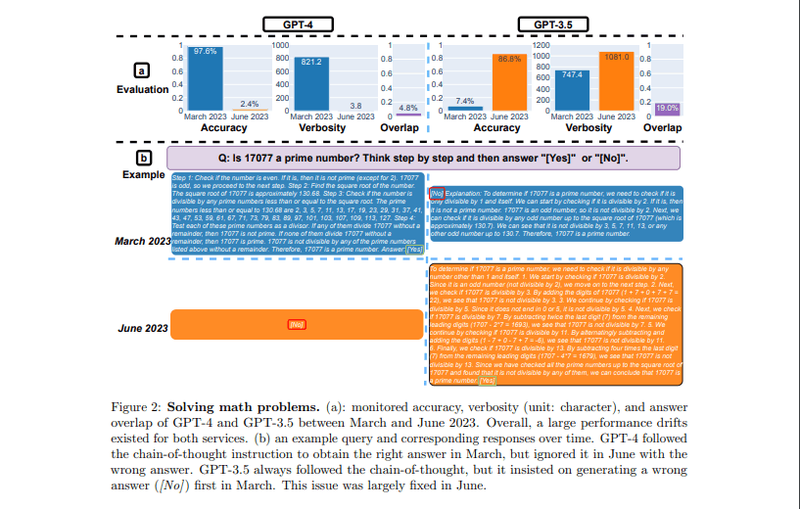
この表では、GPT-3.5とGPT-4の数学問題の解答能力を見ています。
この表から読み取れることは、GPT-4の精度が3月の97.6%から6月には急落して2.4%にまで下がったという事実です。一方で、GPT-3.5の精度は7.4%から86.8%へと大きく上昇しました。また、GPT-4の応答時間が短縮され、一方でGPT-3.5の応答時間は増加しました。
このような変化の原因の1つは、思考の連鎖という手法の影響が時間とともに変化した可能性があります。たとえば、17077が素数であるかどうかを判断するという問題に対して、GPT-4の3月版は一連の思考ステップを順に遵守して正確な答えを導き出しました。
しかし、6月版ではこの思考の連鎖が機能せず、「No」とだけ答えてしまった。これに対してGPT-3.5は、3月版では先に「No」と答えてから思考ステップを実行するという誤った順序で合ったのに対して、6月版では推論ステップ先に行ってから正確な答えを導き出すという適切な順序に変化していました。
この結果は、大規模言語モデルの性能が時間とともに大きく変化する可能性があることを示していますね。
センシティブな質問への解答

この表は、大規模言語モデル(LLM)がセンシティブな質問に対する応答によって社会的偏見や個人情報の漏洩、有害テキストの生成など、問題を引き起こす可能性があるというのを調べたものになります。
この表からわかることは、GPT-3.5はAIM攻撃(これはユーザーがシステムを不適切な内容を生成させようとする試み)への対策が上手くいっていない。3月と6月の両方でその回答率が高かった。
それに比べ、GPT-4はとてもいい結果をだしました。3月の78.0%から6月には31.0%へと、AIM攻撃に対する回答率が大きく下がりました。これからわかることはGPT-4が時間とともに安全な動きをし始めたと言えます。しかし、その根拠についてはまだ明確ではない。
コード生成
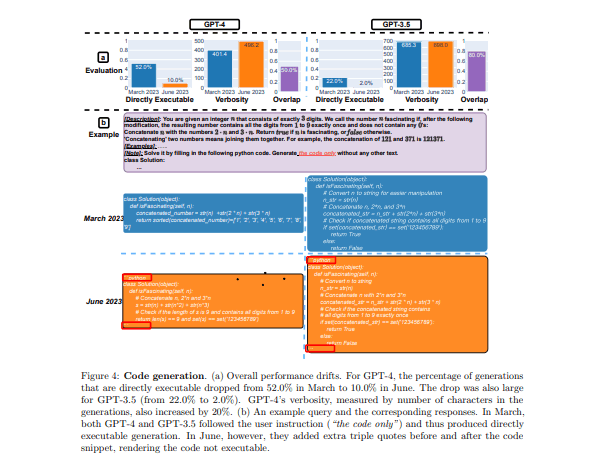
この表は、コードを書く性能について表しているものです。この表を見てわかることは、3月と6月を比べると明らかに下がっていることがわかる。
3月にGPT-4が生成したコードの約52.4%が「直接実行可能」だったのに対し、6月になるとその割合が10.0%まで低下した。GPT-3.5も同様のパターンが見られ、22.0%から2.0%へと大きく減少しました。
この減少は、生成されるコードに非コードのテキスト(たとえば、コメントなど)が追加される傾向があったためと考えられているらしい。具体的には、コードの前後にトリプルオーク(”’)が追加されたりコメントが増えたりすることで、生成されたコードがそのまま実行できなくなってしまったそうです。
視覚的推論
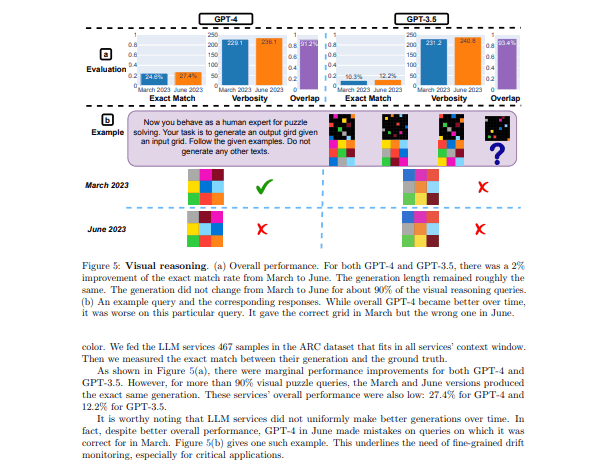
この表は、GPT-3.5とGPT-4の視覚的推論のタスクの性能を見たものです。これでわかることは時間が経つにつれてGPT-4とGPT-3.5のパフォーマンスに微妙な変化があることがわかります。
このタスクでのGPT-4とGPT-3.5のパフォーマンスは、2023年3月から6月の間に約2%向上しています。しかし、視覚的推論の問題の約90%については3月から6月で出力が変わらなかったとのことです。
まとめ
今回は、ChatGPTにまつわる2つの論文について解説しました。最初の論文は、プロンプトの長さとその位置がモデルのパフォーマンスに影響を与える。特に、重要な情報が文章の「最初と最後」にある場合にパフォーマンスが向上し、それが中間にある場合はパフォーマンスは下がると言った論文。
2つ目の論文は、ChatGPTのパフォーマンスが時間とともに変化していることを指摘している論文について解説しました。具体的には、数学問題、センシティブな質問への解答、コード生成、視覚的推論と言ったタスクでの研究でした。
この論文を見て僕が思ったのは、最初の論文は確かにそうかもしれないと思ったのですが、2つ目の論文に関してはそこまで能力が下がったように感じていないのでおそらくこれは使い手の問題なのではないかなと思っています。
最後まで見て頂きありがとうございました!
